Writing
A working taxonomy of LLM attacks: against, using, and within
A practical scheme for classifying LLM attacks by their relationship to the model: against it, using it, or within it, and how it relates to the OWASP LLM Top 10 and MITRE ATLAS.
The LLM threat landscape is expanding fast and feels chaotic. New attack names appear every week: prompt injection, jailbreaks, data poisoning, model extraction. Practitioners need a way to make sense of it at a glance.
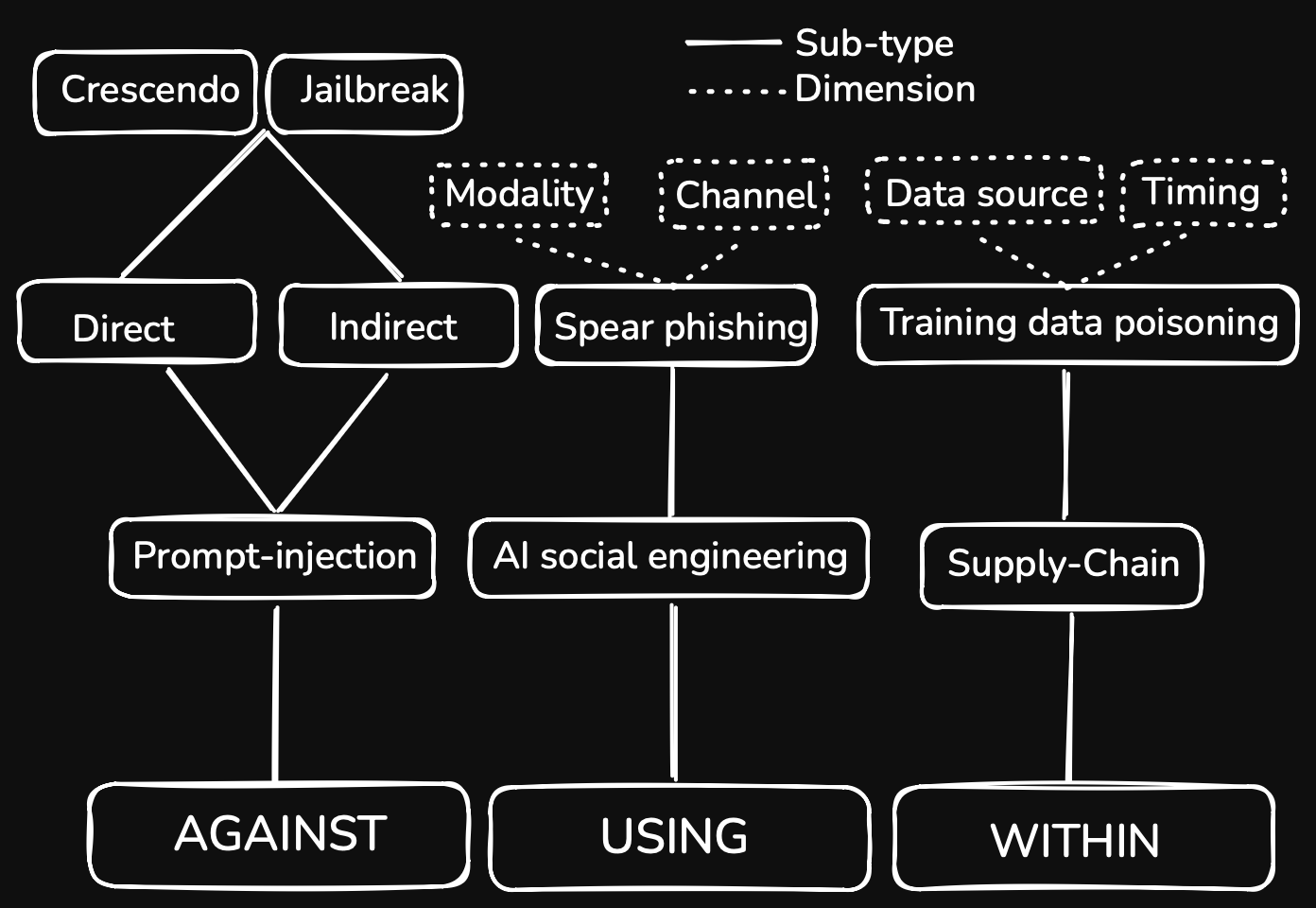
Every attack on an LLM can be placed in one of three relationships to the model: against it, using it, or within it. Against it means the model itself is the target, its behavior manipulated through its inputs at runtime. Using it means the model is the weapon: its capabilities are turned to malicious ends against some other target (spear-phishing, finding vulnerabilities, creating malware). Within it means attacking its supply chain, the layers that lie underneath or above the foundation model, poisoning the training-data corpora or pre-trained components, for example.
A prominent example of attacks against the model are prompt injections (direct and indirect), where jailbreaks are a special case. Most taxonomies have a hierarchy-like structure. If we return to the prompt-injection example, the top layer is against the large language model, followed by prompt injection, followed by direct and indirect prompt injection, followed in turn by jailbreak or crescendo techniques. You can expand the tree for as long as it remains useful. The structure also shows the relationship between different types of attacks: what is a category of what, and most often the root attack is also the first that was developed in a given domain.
For using the model, some examples include AI-assisted social engineering (phishing generation), automated reconnaissance via agentic browsing, and malicious code generation without guardrails. If we follow the AI-assisted social engineering branch, it leads to AI-generated spear-phishing campaigns. Next is the modality of the campaign: is it audio, video, text, or a mix? The channel through which it is conducted also matters. Another aspect is whether it's combined with other techniques, such as email spoofing.
Lastly, within the model covers the most varied attack patterns. These include attacks on the components the model is built from or embedded in: the pipeline, supply chain, training data, plugins/tools, and surrounding application layers. An example of a branch is the supply chain. The next element is training-data poisoning. From there, we can granulate further by describing how the poisoning happens, for instance which data source is affected (poisoned web scrapes versus poisoned fine-tuning sets). The timing matters too: pretraining versus the RLHF stage are meaningful differentiators in this domain.
How this relates to OWASP and MITRE ATLAS
If you already work with the OWASP LLM Top 10 or MITRE ATLAS, a fair question is what a three-part scheme adds. The answer is that it organizes by a different principle. The OWASP Top 10 is a risk-ranked list: the ten most critical vulnerabilities, ordered by prevalence and impact. MITRE ATLAS is a matrix of adversarial tactics and techniques, modelled on ATT&CK. Neither is wrong; they answer different questions (“what should I prioritize?” and “what technique is the adversary using?”). AGAINST / USING / WITHIN answers a third: what is the attack's relationship to the model itself?
That lens makes the existing frameworks easier to navigate, because most OWASP entries map cleanly into one of the three buckets:
- AGAINST (the model is the target, manipulated through its inputs at inference): LLM01 Prompt Injection, LLM02 Sensitive Information Disclosure, LLM07 System Prompt Leakage, and the DoS / denial-of-wallet portion of LLM10 Unbounded Consumption.
- WITHIN (the components the model is built from or embedded in): LLM03 Supply Chain, LLM04 Data and Model Poisoning, LLM05 Improper Output Handling, LLM08 Vector and Embedding Weaknesses, and the model-extraction portion of LLM10.
- Boundary cases worth naming honestly: LLM06 Excessive Agency sits at the edge of AGAINST and WITHIN. The trigger is often an against-style manipulated input, but the weakness is a within-style over-permissioned tool/permission layer. A taxonomy earns trust by acknowledging its edges rather than hiding them, and excessive agency is genuinely a hinge between two of the buckets.
The revealing part is what doesn't map. USING, the model turned into a weapon against a third party (AI-generated spear-phishing, automated reconnaissance, malware generation), has almost no home in the OWASP LLM Top 10, because that list is about securing your LLM application, not about the model being used as an attacker's tool. MITRE ATLAS captures some of it, but it's under-served by the application-security framing. That gap is the point: the USING category names a whole class of LLM-enabled threat that a defender of an LLM application will systematically overlook, because their framework doesn't prompt them to think about it.
Additionally, misinformation doesn't map cleanly to any of the three because it's frequently not adversarial; it's an inherent reliability failure of stochastic generation. When it is weaponized (poisoned sources, induced hallucination), it has an AGAINST or WITHIN character; when it's just the model being confidently wrong, it sits outside an attack taxonomy entirely.
So the goal of this taxonomy is not to replace OWASP's framework; it serves a different purpose. The two sit orthogonal to each other: OWASP's framework deals with risks; mine deals with attacks.
The point of a taxonomy is not elegance for its own sake; it's that it changes how you think. Faced with the next attack technique that appears (and one will, probably before this article is a month old), you don't have to file it as another loose entry in an ever-growing list. You ask one question: is this attack against the model, using the model, or within its components? That single question places the threat, tells you which defenses are even relevant, and shows you what it's related to. A new jailbreak variant is an AGAINST problem, so input-handling and output-filtering controls apply. A poisoned dependency is a WITHIN problem that no amount of prompt-hardening will touch. A model spun up to generate phishing at scale is a USING problem that your application-security checklist won't even mention. The scheme is the first filter, not the whole answer, but a good first filter is what turns a chaotic landscape into something you can reason about.
This is also, in practice, how I approach an audit: before testing anything, I map a system's attack surface across the three relationships, so that nothing falls through the cracks, including the categories the standard frameworks under-serve.